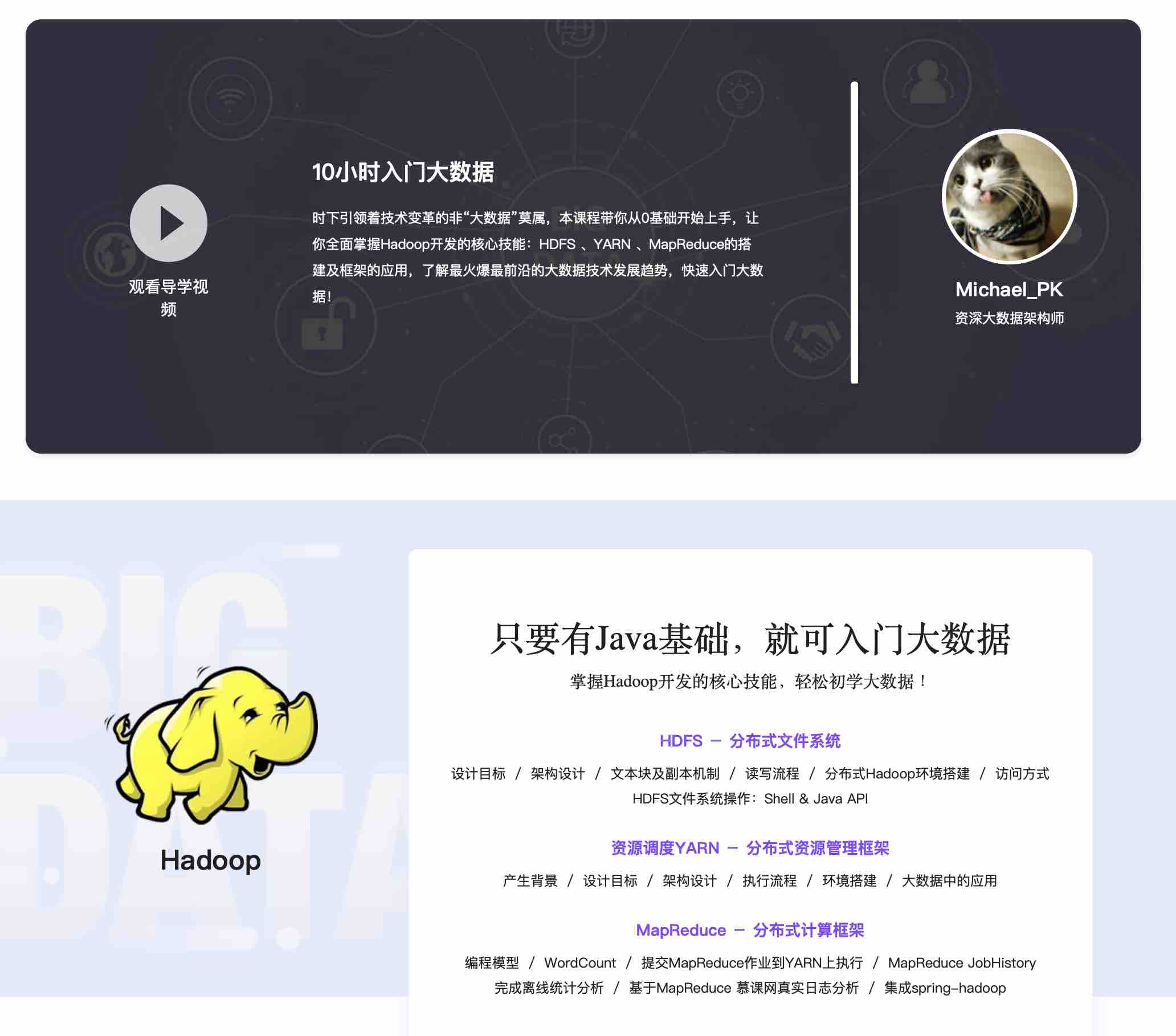
10小时入门大数据【已完结 MK128】

-
第1章 大数据概述
本章将从几则故事说起,让大家明白大数据是与我们的生活息息相关的,并不是遥不可及的,还会介绍大数据的特性,以及大数据对我们带来的技术变革,大数据处理过程中涉及到的技术
- 1-1 导学
- 1-2 章节安排_
- 1-3 OOTB镜像文件和虚拟机的使用
- 1-4 说两则故事说起
- 1-5 大数据与生活息息相关
- 1-6 大数据基本概念
- 1-7 大数据带来的挑战
- 1-8 如何应对大数据带来的挑战
- 1-9 -如何学好大数据
-
第2章 初识Hadoop
本章节将带领大家认识Hadoop以及Hadoop生态系统、Hadoop的发展史、Hadoop的优缺点、Hadoop的三个核心组件、Hadoop发行版的选择以及Hadoop在企业中的案例分享,为后续深入讲解Hadoop打下坚实的基础
- 2-1 章节安排
- 2-2 Hadoop概述
- 2-3 2.03-Hadoop核心组件之HDFS
- 2-4 2.04-Hadoop核心组件之YARN
- 2-5 2.05-Hadoop核心组件之MapReduce
- 2-6 2.06-Hadoop优势
- 2-7 2.07-Hadoop发展史
- 2-8 2.08-Hadoop生态系统
- 2-9 2.09-Hadoop常用发行版及选型
- 2-10 2.10-Hadoop应用案例
-
第3章 分布式文件系统HDFS
本章将从Hadoop的设计目标、架构及副本的脚本带大家详细剖析,快速搭建单节点伪分布式HDFS的实验环境,并讲解使用hdfs shell以及Java API的方式操作HDFS文件系统,并详细分析HDFS文件的读写流程,使得大家对Hadoop分布式文件系统HDFS有深刻的认识以及使用…
- 3-1 -课程目录-
- 3-2 -普通分布式文件系统的设计思路
- 3-3 HDFS概述及设计目标
- 3-4 HDFS架构
- 3-5 HDFS副本机制
- 3-6 HDFS副本存放策略
- 3-7 JDK安装&ssh安装&ssh免密码登陆配置
- 3-8 HDFS伪分布式环境搭建
- 3-9 HDFS shell操作
- 3-10 Java操作HDFS开发环境搭建
- 3-11 Java API操作HDFS文件系统
- 3-12 HDFS写数据流程
- 3-13 HDFS读数据流程
- 3-14 HDFS文件系统的优缺点
-
第4章 分布式资源调度YARN
本章将从YARN的产生背景、YARN的架构及执行流程的角度带大家认知Hadoop的资源调度框架YARN,快速搭建单节点伪分布式YARN的实验环境并掌握如何提交一个官方自带的MapReduce作业提交到YARN上运行
- 4-1 -课程目录
- 4-2 -YARN产生背景
- 4-3 -YARN架构
- 4-4 -YARN执行流程
- 4-5 -YARN环境搭建
- 4-6 -初识提交PI的MapReduce作业到YARN上执行
-
第5章 分布式计算框架MapReduce
本章将从架构、优缺点、编程模型等角度带大家认识Hadoop的分布式计算框架MapReduce,掌握MapReduce应用程序的开发,学会配置JobHistory Server
- 5-1 -课程目录
- 5-2 -MapReduce概述
- 5-3 -从WordCount案例说起MapReduce编程模型
- 5-4 -MapReduce执行流程
- 5-5 -MapReduce核心概念
- 5-6 -MapReduce1.x架构
- 5-7 -MapReduce2.x架构
- 5-8 -Java版本wordcount功能实现
- 5-9 -Java版本wordcount功能重构
- 5-10 -Combiner应用程序开发
- 5-11 -Partitioner应用程序开发
- 5-12 JobHistory使用
-
第6章 Hadoop项目实战
本章将通过对慕课网主站的访问日志进行分析的项目实战,来将前面几个章节讲解的知识点串联起来,综合使用Hadoop的技术进行离线统计分析
- 6-1 -课程目录–
- 6-2 用户行为日志概述
- 6-3 离线数据处理架构
- 6-4 项目需求
- 6-5 功能实现之UserAgent解析类测试
- 6-6 功能实现之单机本地完成需求统计
- 6-7 使用MapReduce完成需求统计
- 6-8 功能扩展思路
-
第7章 Hadoop分布式集群搭建
本章将带领大家搭建一个三个节点的分布式Hadoop集群环境,让大家对于Hadoop集群的安装有更深入的认识,并将项目实战案例运行在分布式集群环境中
- 7-1 -课程目录
- 7-2 -分布式环境搭建之环境介绍
- 7-3 -分布式环境搭建前置配置之ssh免密码登陆
- 7-4 -分布式环境搭建前置配置之JDK安装
- 7-5 -分布式环境搭建集群搭建之Hadoop配置及分发
- 7-6 -分布式环境搭建Hadoop格式化及启停
- 7-7 -分布式环境HDFS及YARN的使用
- 7-8 -将Hadoop项目运行在Hadoop集群之上
-
第8章 Hadoop集成Spring的使用
本章将带领大家使用Java社区中最流行的Spring框架来整合Hadoop的使用
- 8-1 -课程目录
- 8-2 -Spring Hadoop概述
- 8-3 -Spring Hadoop开发环境搭建及访问HDFS文件系统
- 8-4 -Spring Hadoop配置文件详解
- 8-5 -Spring Boot访问HDFS文件系统
- 8-6 -Spring Hadoop其他
-
第9章 前沿技术拓展: Spark/Flink/Beam
本章将带领大家认识当前大数据领域中非常火爆的三个框架:Spark、Flink以及Beam,并使用这三个框架完成词频统计分析操作,为大家以后更加深入的学习这几个框架打下坚实的基础
- 9-1 -课程目录
- 9-2 -吐槽MapReduce
- 9-3 -Spark特点
- 9-4 -Spark与Hadoop深入对比
- 9-5 -Spark开发语言及运行模式介绍
- 9-6 -Scala&Maven安装
- 9-7 -Spark环境搭建及wordcount案例实现
- 9-8 -Flink概述
- 9-9 -使用Flink完成wordcount统计
- 9-10 -Beam概述
- 9-11 -将WordCount的Beam程序以多种不同Runner运行
- 9-12 -课程目录
-
第10章 Hadoop3.x新特性
本章将带来大家学习Hadoop3.x版本的一些新特性,实时跟上Hadoop社区的发展
- 10-1 -课程目录
- 10-2 -Hadoop3.x概述
- 10-3 -Hadoop3.x新特性之Common改进
- 10-4 -Hadoop3.x新特性之HDFS改进
- 10-5 -Hadoop3.x新特性之YARN改进
- 10-6 -Hadoop3.x新特性之MapReduce改进
- 10-7 -Hadoop3.x新特性之其他