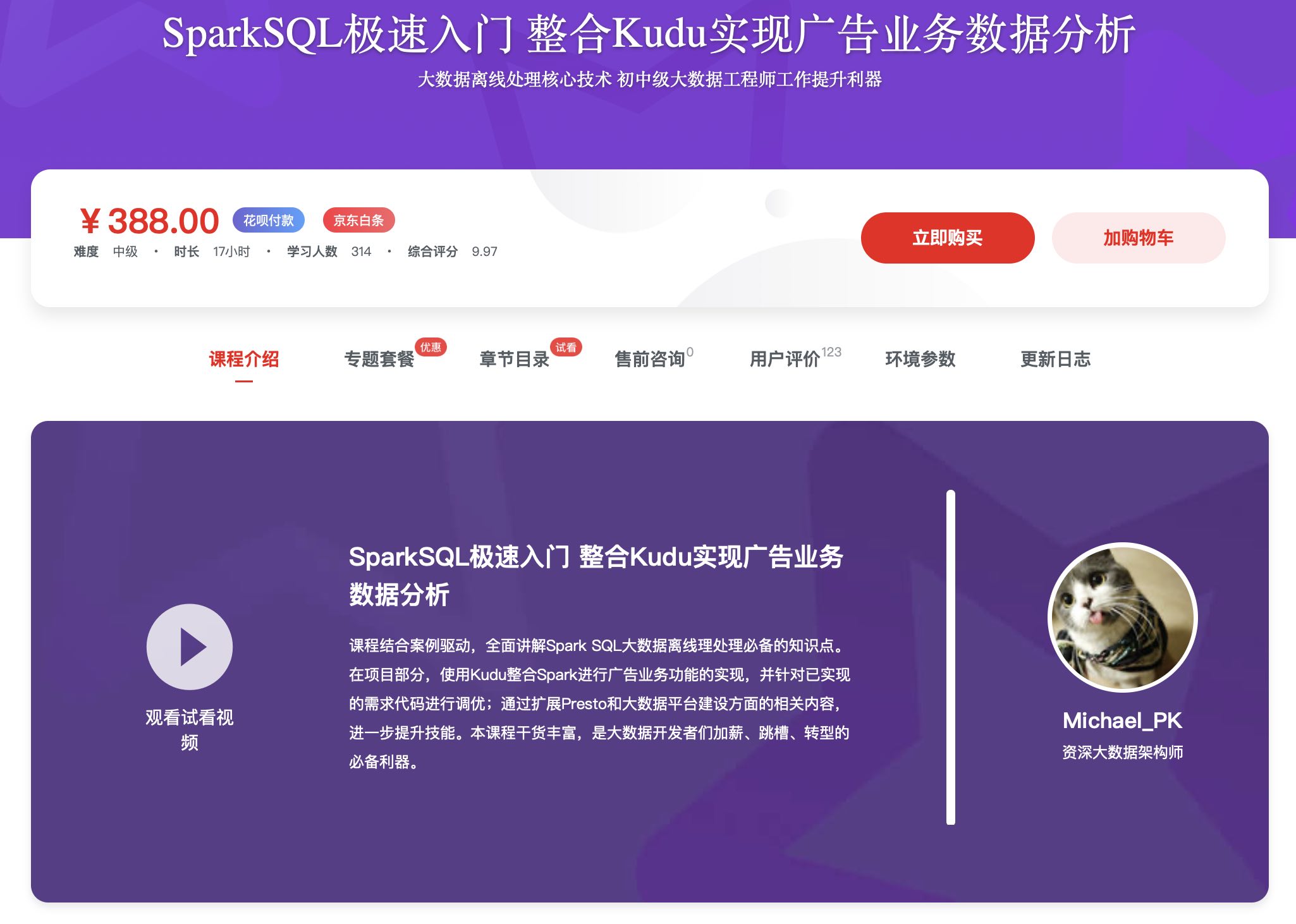
SparkSQL极速入门 整合Kudu实现广告业务数据分析【已完结 9G】


-
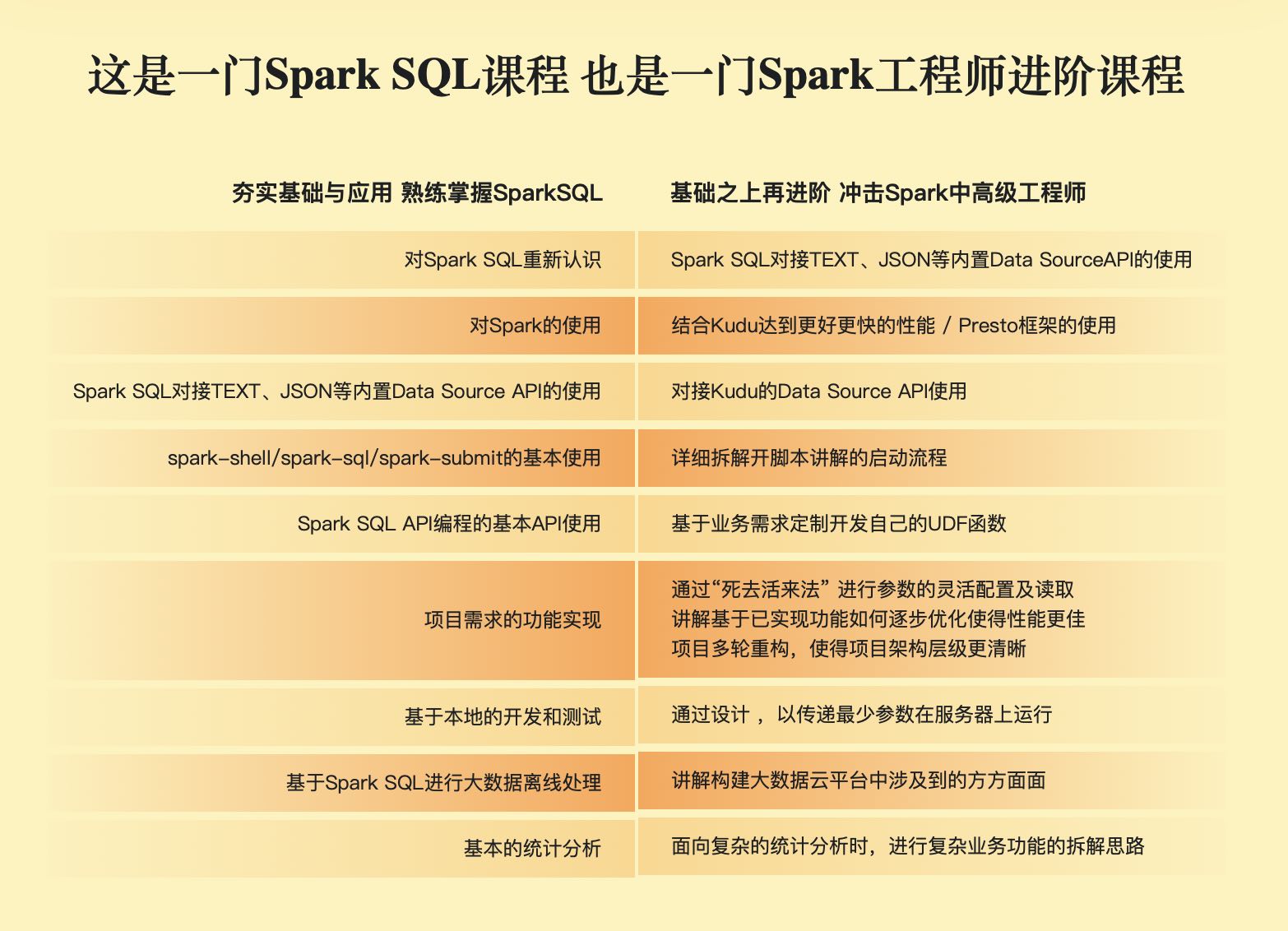
第1章 课程介绍&学习指南
本章会对这门课程进行说明并进行学习方法介绍。
- 1-1 课程导学试看
- 1-2 ***学前必读***(助你平稳踩坑,畅学无忧,课程学习与解决问题指南)
-
第2章 为什么要学Spark
Spark作为近几年最火爆的大数据处理技术,是成为大数据工程师必备的技能之一。本章节将从如下几个方面对Spark进行一个宏观上的介绍:Spark产生背景、特性、环境部署、Spark与Hadoop的对比、Spark开发语言及运行模式等。
- 2-1 课程目录
- 2-2 MapReduce的槽点
- 2-3 Spark特性详解
- 2-4 Spark Stack
- 2-5 OOTB环境的使用
- 2-6 JDK部署
- 2-7 Maven部署
- 2-8 IDEA部署
- 2-9 HDFS部署
- 2-10 YARN部署
- 2-11 Hive部署
- 2-12 Spark运行模式
- 2-13 使用IDEA和Maven开发第一个Spark应用程序
- 2-14 词频统计按照单词出现次数的降序排列
- 2-15 local模式下spark-shell的使用
- 2-16 local模式下使用spark-submit提交Spark应用程序
- 2-17 YARN模式下提交Spark应用程序
- 2-18 Standalone模式下提交Spark应用程序
- 2-19 Hadoop和Spark生态圈对比
- 2-20 Hadoop与Spark对比
- 2-21 Spark和Hadoop的相互协作
-
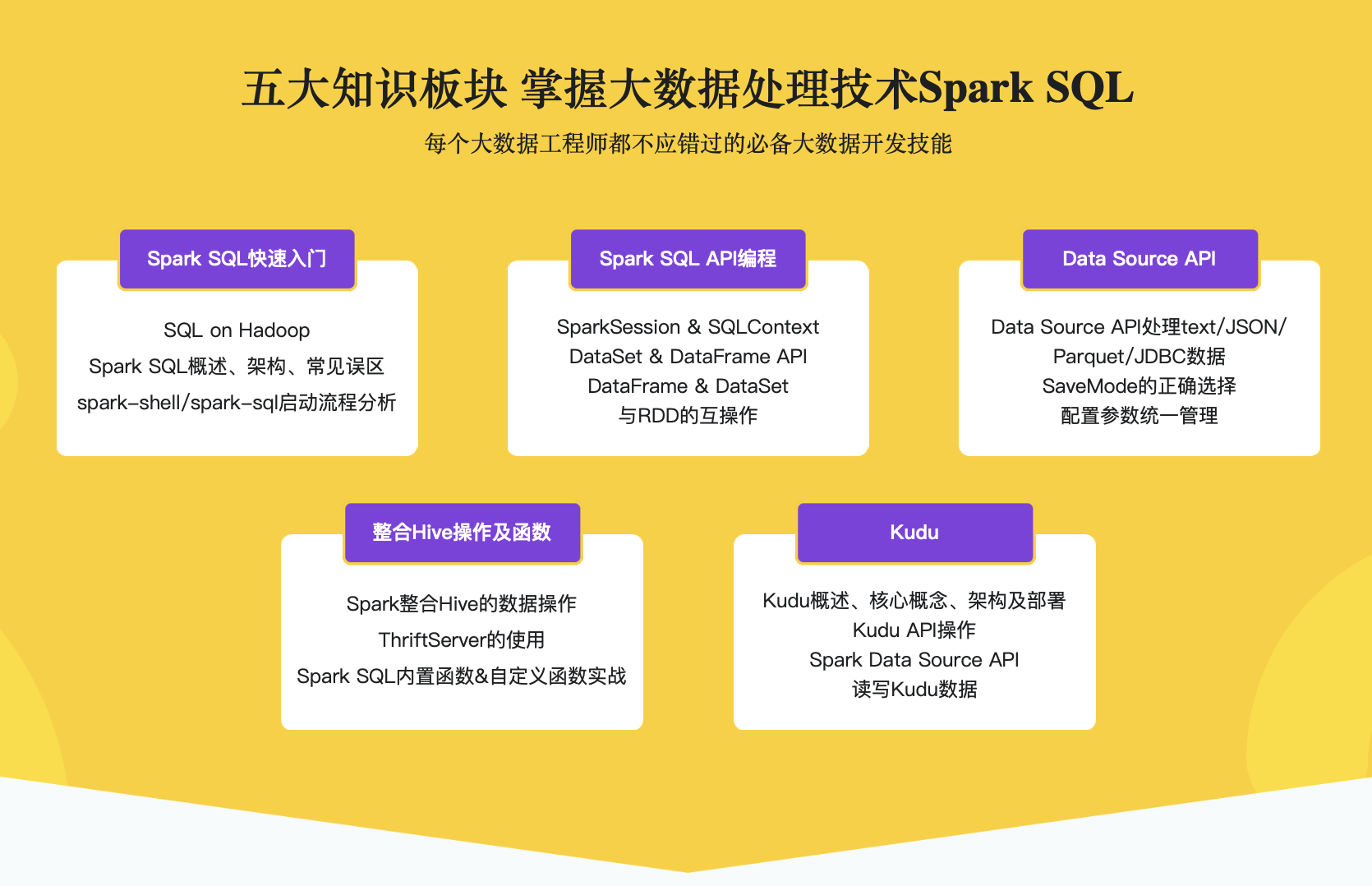
第3章 Spark SQL快速入门
Spark SQL面世已来,深受小伙伴们的喜爱,继续为Spark用户提供高性能SQL on Hadoop解决方案,还为Spark带来了通用、高效、多元一体的结构化数据处理能力。本章将从为什么要学习SQL/Spark SQL、SQL on Hadoop框架、Spark SQL概述、架构及快速入门,这几个角度进行展开讲解…
- 3-1 课程目录
- 3-2 为什么需要SQL
- 3-3 SQL on Hadoop
- 3-4 详解Spark SQL是什么以及常见误区解读
- 3-5 Spark SQL概述
- 3-6 为什么要学习Spark SQL
- 3-7 Spark SQL架构
- 3-8 spark-shell使用详解
- 3-9 spark-sql使用详解并结合讲解Catalyst的执行过程
- 3-10 spark-shell启动流程分析之uname以及case匹配的使用试看
- 3-11 spark-shell启动流程分析之dirname和if的使用
- 3-12 spark-shell启动流程分析之传递参数详解
- 3-13 spark-shell启动流程分析之spark-submit
- 3-14 spark-sql启动流程分析
-
第4章 Spark SQL API编程
DataFrame&Dataset是Spark2.x中最核心的编程对象,Spark2.x中的子框架能够使用DataFrame或Dataset来进行数据的交互操作。本章将从DataFrame的概述、DataFrame对比RDD、DataFrame API操作等方面对DataFrame做详细的编程开发讲解。
- 4-1 课程目录
- 4-2 认知SparkSession
- 4-3 了解SQLContext
- 4-4 认识DataFrame
- 4-5 DataFrame API基本使用
- 4-6 DataFrame中前N条的取值方式
- 4-7 通过实战案例学习DataFrame常用API
- 4-8 Dataset概述及操作
- 4-9 DataFrame vs Dataset
- 4-10 Interoperating with RDD概述
- 4-11 实现方式一
- 4-12 实现方式二
-
第5章 Data Source API
Spark SQL中的核心功能,可以使用Data Source API非常方便的对存储在不同系统上的不同格式的数据进行操作。本章将讲解如何使用Data Source API来操作text、json、Parquet、JDBC中的数据以及综合使用。
- 5-1 课程目录
- 5-2 Data Source概述试看
- 5-3 text数据源读写案例
- 5-4 SaveMode的使用详解
- 5-5 json数据源案例
- 5-6 Data Source API标准写法
- 5-7 Parquet数据源案例
- 5-8 Data Source格式转换
- 5-9 jdbc数据源案例
- 5-10 通过统一配置参数管理工程中使用到的参数
-
第6章 整合Hive操作及函数
如何使用Spark对接已有数据仓库Hive中的数据,这是在生产中常见的问题。本章将讲解如何使用Spark无缝对接Hive中已有数据进行处理,thriftserver的使用、以及如何使用Spark SQL中的内置函数以及自定义函数。
- 6-1 课程目录
- 6-2 Spark对接Hive的原理及实操
- 6-3 thriftserver&beeline的使用
- 6-4 使用代码连接Server
- 6-5 Server模式vs例行作业模式(思考题)
- 6-6 hive数据源案例
- 6-7 Spark SQL内置函数实战
- 6-8 Spark SQL自定义UDF实战
-
第7章 Kudu入门
近两年,KUDU在大数据平台的应用越来越广泛,她是Cloudera开源的运行在Hadoop平台上的列式存储系统,能够为我们提供“fast analytics on fast data”。本章将从Kudu的核心概念、架构、部署、API操作以及Spark整合Kudu的使用展开讲解。
- 7-1 课程目录
- 7-2 kudu概述&核心概念&架构
- 7-3 kudu部署
- 7-4 API操作之创建表
- 7-5 API操作之插入数据&删除表&数据查询
- 7-6 API操作之修改表数据及表名
- 7-7 Spark整合Kudu的读写操作
-
第8章 基于Spark SQL和Kudu的广告业务项目实战(一)
本章使用Spark SQL整合Kudu对广告业务项目进行统计分析操作。涉及到的过程有:项目架构、数据清洗、数据统计、结果入库、项目重构。通过本实战项目将Spark SQL和Kudu中的知识点融会贯通,达到举一反三的效果 。
- 8-1 课程目录
- 8-2 广告业务背景
- 8-3 项目需求
- 8-4 项目架构及数据处理流程
- 8-5 日志字段说明
- 8-6 需求一之IP规则库解析
- 8-7 需求一之使用API编程完成日志ip字段解析
- 8-8 需求一之使用SQL方式完成日志ip字段解析
- 8-9 需求一之ODS数据落地到Kudu
- 8-10 需求一之落地到Kudu表重构
- 8-11 需求二功能实现
- 8-12 需求一二代码结构大重构
-
第9章 基于Spark SQL和Kudu的广告业务项目实战(二)
基于上一章节做更复杂维度的统计分析,作业的封装、调度。
- 9-1 课程目录
- 9-2 需求三之第一阶段统计功能实现
- 9-3 需求三之第二阶段统计功能实现
- 9-4 需求三之统计结果落地到Kudu
- 9-5 需求四功能实现
- 9-6 通过参数传递到Spark作业重构代码并打包
- 9-7 将项目运行在服务器上
- 9-8 定时调度提交Spark作业到服务器运行
- 9-9 本章节小结
-
第10章 Spark调优策略
Spark应用调优是一个在生产上或者面试中老生常谈的问题,本章节将从资源设置、广播变量、Shuffle、JVM引发的相关角度逐一展开讲解。
- 10-1 课程目录
- 10-2 调优之资源设置
- 10-3 广播变量在Spark中的使用一
- 10-4 广播变量在Spark中是使用二
- 10-5 广播变量思考题(重要)
- 10-6 Shuffle调优
- 10-7 Spark与GC相关概念理解
- 10-8 JVM GC引起的问题调优
- 10-9 其他调优
-
第11章 Presto初识
Preso也是当下用的非常多的一种SQL on Hadoop的解决方案。本章节将从Presto架构、API操作等角度出发,通过一个案例来进行综合演练。
- 11-1 课程目录
- 11-2 Presto是什么&能做什么&谁在使用它
- 11-3 Presto架构
- 11-4 Presto部署
- 11-5 整合MySQL Connector
- 11-6 整合Hive Connector
- 11-7 Presto整合多个Connector操作
- 11-8 Presto API操作
-
第12章 云平台建设的思考
本章将从如何建设大数据云平台的角度,涉及到数据平台的N个方面,是小伙伴以后进入大厂工作奠定基础,同时也会从Spark vs Flink的角度来为小伙伴们分析选型时的疑惑。
- 12-1 课程目录
- 12-2 大数据项目和平台的差异性对比
- 12-3 认知云平台能为我们提供的能力
- 12-4 大数据云平台功能架构
- 12-5 数据湖架构
- 12-6 数据存储和计算角度剖析
- 12-7 资源角度剖析
- 12-8 兼容性角度剖析
- 12-9 执行引擎和运行方式适配角度剖析
- 12-10 Spark和Flink的选择
-
第13章 (讨论群内直播内容分享)Spark3新特性
Spark3是一个里程碑版的版本,其中包含很多新的特性,本次直播中主要带大家知晓新特性有哪些,以及讲解动态分区裁剪、外部数据源V2、自适应查询执行等相关知识。
- 13-1 Spark概述
- 13-2 Spark3.x新特性
- 13-3 DataSource API V2
- 13-4 动态分区裁剪
- 13-5 自适应查询执行